顾名思义,这一章就是介绍如何管理内存,系统给memory manager下的定义是:
The part of the operating system that manages (part of) the memory hierarchy is called the memory manager. It’s job is to efficiently manage memory: keep track of which parts of memory are in used, allocate memory to processes when they need it, and deallocate it when they are done.
No Memory Abstraction
在没有memory abstraction的时候,programmer直接面对physical memory,把physical memory直接暴露有很多缺点,比如很容易使操作系统崩溃,也不能有效的运行multi processes。 为什么说不能有效的运行multi processes呢?因为存在一个overwriting的问题,第二个想同时运行的程序会覆盖第一个程序。
Three ways to implement
就算是没有内存抽象,要管理内存也有不同的方式,比如下图中的a,将操作系统放在RAM中,其余内存用来放User Program。
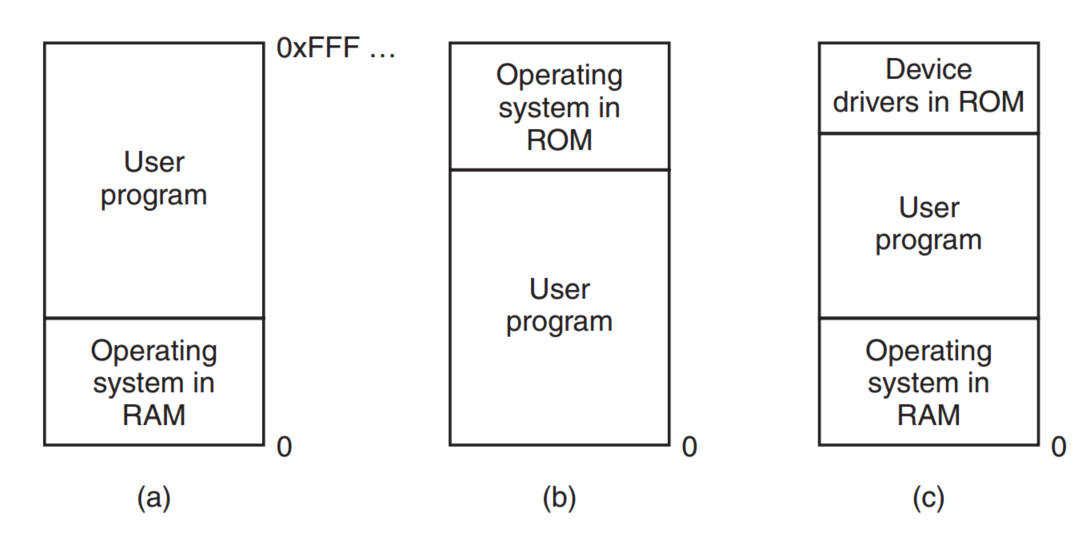
How to run multiple programs at the same time
前面提到在没有内存抽象的时候很难同时运行多个processes,但是还是有办法的,不过这些办法或多或少都有缺陷。
Threads
只运行一个process,这个process里有多个不同的threads。 其实也就是multi threads。但我们的本意是同时让多个不相关的工作同时进行。
IBM 360 solution
IBM 360创造了一个简单的模型来解决这个问题,它把memory分成块,每个块都有protection key,而每个程序也有自己的PSW(program status word),写入第一个程序后,如果要写第二个程序,先比较protection key,
然后再决定是否写入,其实也就是分辨了已经被写的块和尚未写入的块,以完成同时运行multi processes的目标。
但是这么做也有缺点,每个程序所用的都是absolute physical memory,可能会造成instructions的错乱。
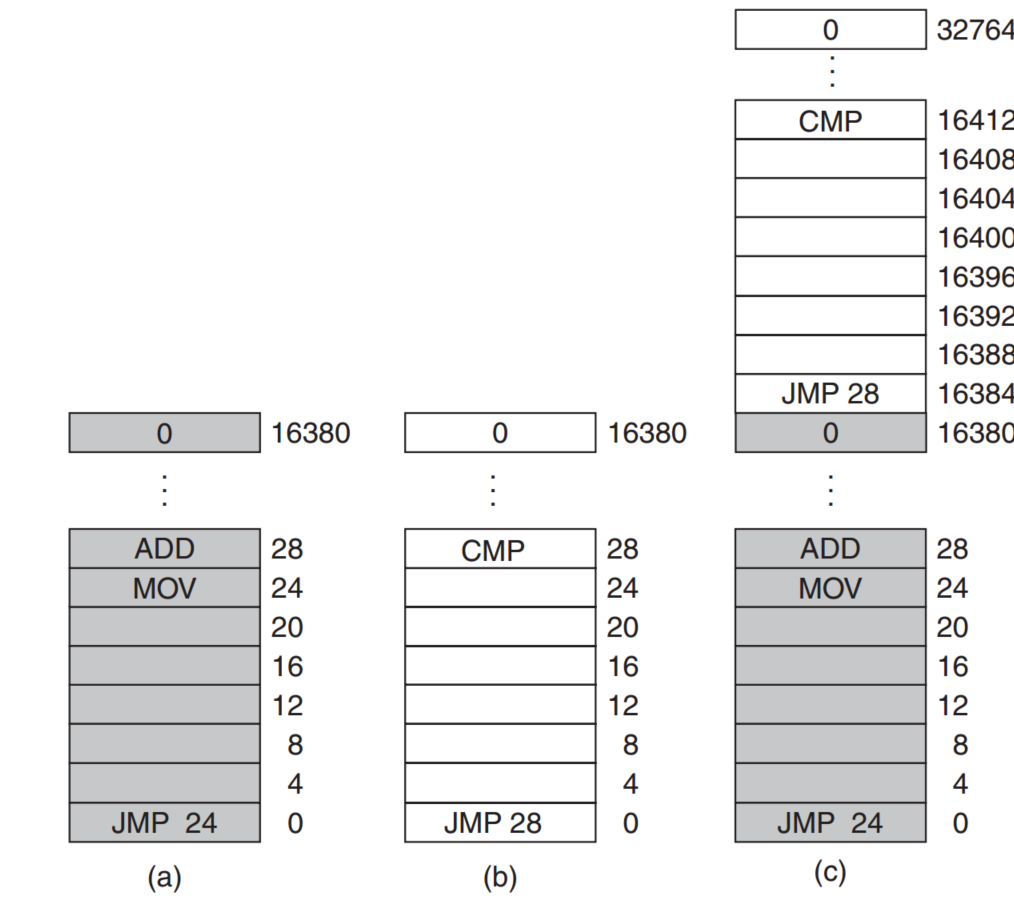
比如说上图,图c同时运行program A和program B,program B的 JMP 28指令原意是想跳转到16384+28,但是现在会直接跳到28,也就是A的指令。
IBM后来又提出了一个static relocation技术,为了解决上面那个问题,也就是让B能够定位到16384+28而不是28。
static relocation的优点是:Require no hardware support. 缺点是:
- Slow down loading
- Once loaded, the code or data of the program can’t be moved into the memory without further relocation。
- The loader needs some way to tell what is and address and what is a constant.
Memory Abstraction: Address Space
我们要进行内存管理,其实要解决的是两个问题:Relocation和Protection。
Relocation:How does a task or process run in different locations in main memory?
Protection:How does the system prevent processes interfering with each other?
而所谓的address space的概念就是:The set of addresses that a process can use to address memory. Each process has its own address space; independent of other processes。 这项技术也被称为Dynamic Relocation或是Dynamic Binding:Map each process’s address space onto a different part of physical memory.
Base and Limit Registers
实现上述所说的dynamic relocation需要硬件的支持,equip CPU with two special hardware registers:base and limit。
base register记录着address space开始的位置,而limit register记录这address space的长度。
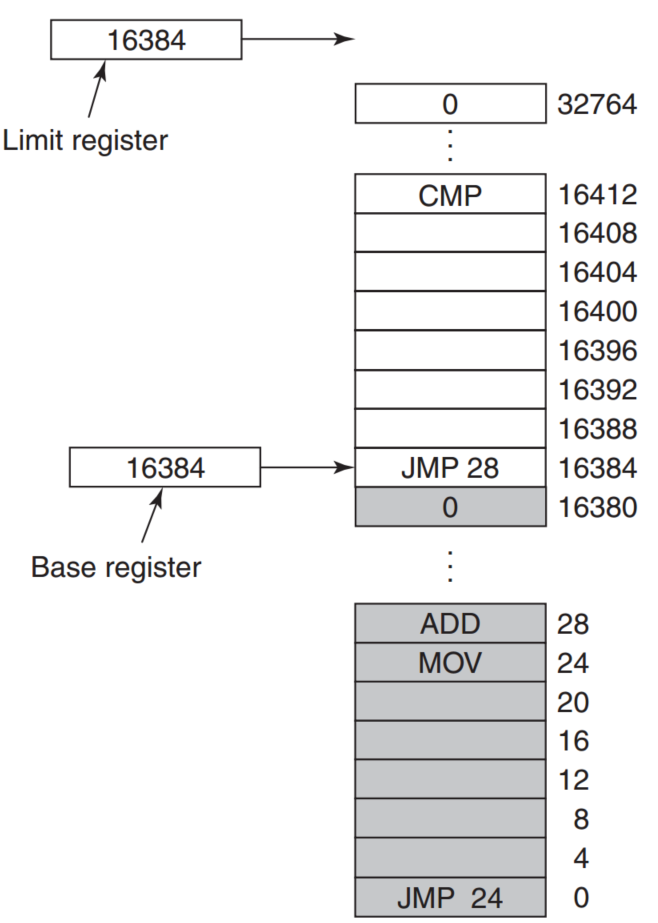
如上图所示,A程序的base limit分别是0和16384,B的base limit 分别是16384和16384.
这种方式的优点是:
- OS can easily move process during execution
- OS can allow process to grow over time(OS just changes limit register or moves it)
- Simple, fast hardware(Two special registers, add, & compare)
缺点是:
- Slows everything (add on every reference)
- Can’t share memory between processes
- Process limited to physical memory size
- Complicates memory management
Swapping
如果内存足够大,大到可以装下所有programs的话,那么没什么问题,但实际上memory的大小是受限的,所以如果memory被programs占满了,又有新的程序要运行,那怎么办呢? 这就需要swapping技术,或者后来所说的virtual memory。
所谓的swapping技术,其实也就是把旧的program从内存中移出把新的program放在内存的过程。这也造成了一个新的问题,可能会造成内存碎片!这些碎片如果得不到合理利用,会非常浪费内存空间。
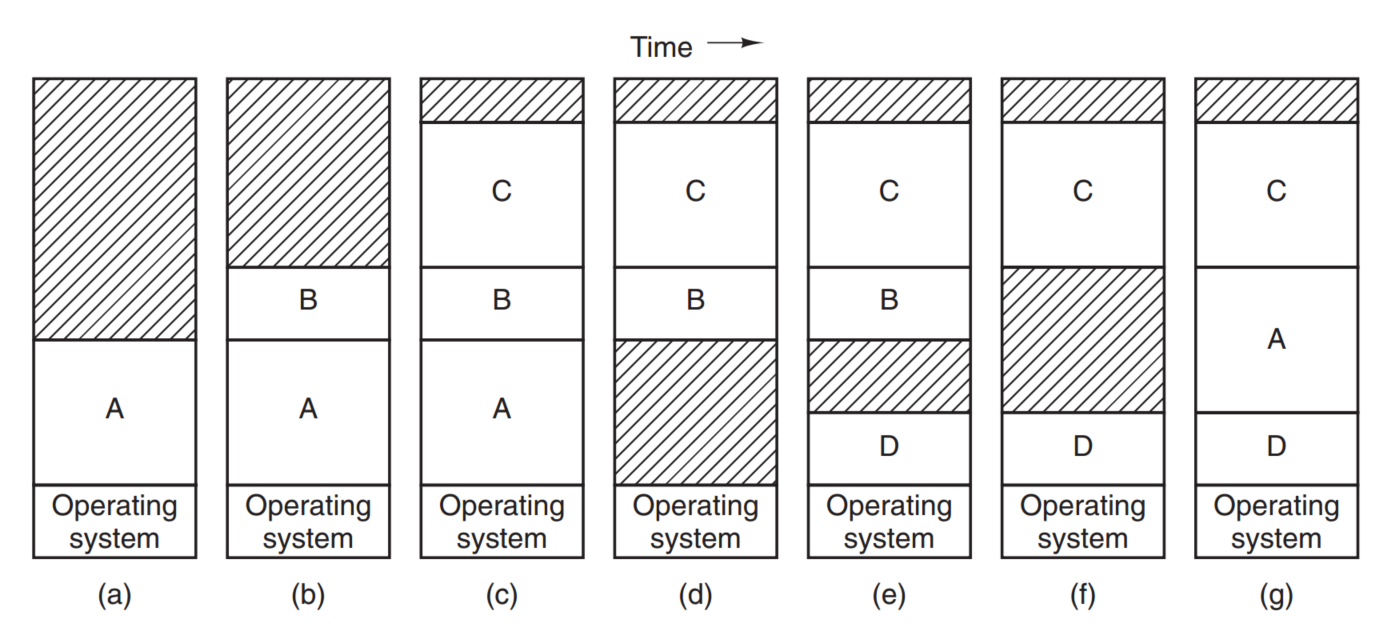
如上图所示,随着时间的推移,所造成的内存碎片。 swapping还带来的一个问题是:如果process太大了,是装不进去内存的,那么也就没有办法运行了。
Manageing Free Memory
上面提到,swapping技术会带来memory holes,我们必须采取措施去追踪内存的使用,一种方式是使用bitmaps,一种是使用linked list。
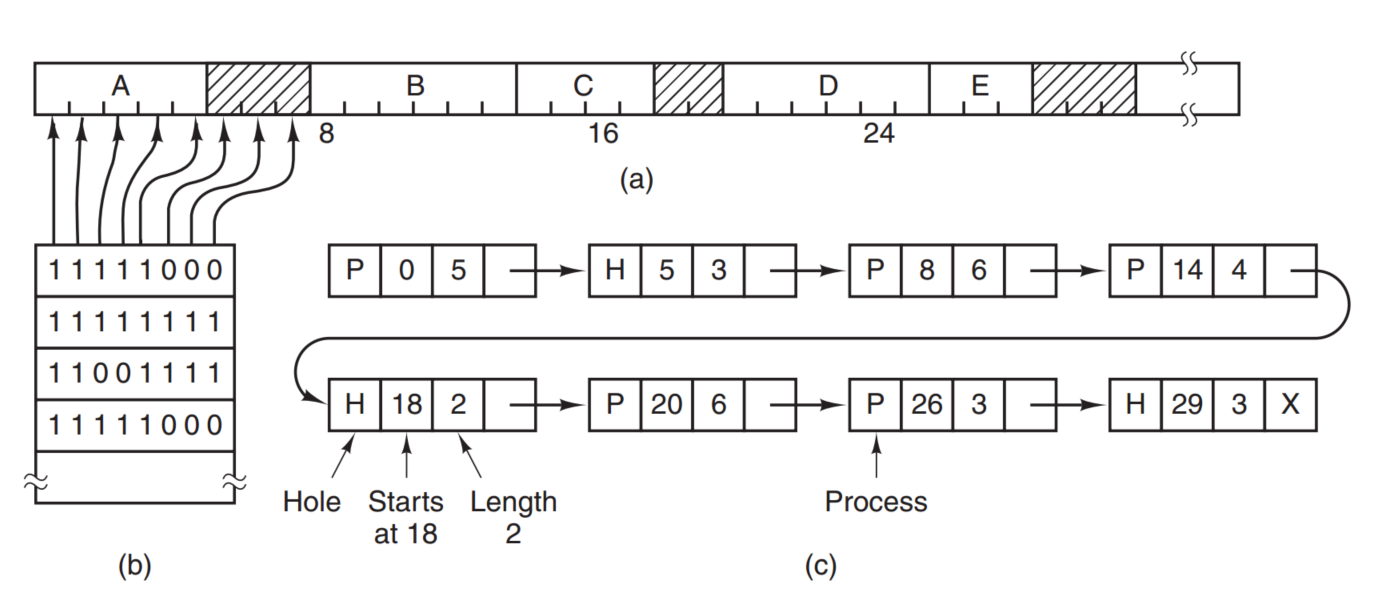
如上图所示,a是五个processes:A B C D E和它们所造成的holes,b是使用bitmaps来记录holes,c是使用linked lists来记录Holes。
为了充分利用这些holes,我们也有着相应的策略。
Storage Placement Strategies
- First Fit: 填补第一个适合的hole。
- Next Fit:填补上一个hole之后适合的hole。
- Best Fit:填补最适合的hole。
- Worsr Fit:填补最大的hole。
- Quick Fit:Maintains separate lists for some of the more common sizes requested. When a request comes for placement it finds the closest fit.
Virtual Memory
Overview
前面提到,virtual memory是实现address space的一种方式,它比base/limit register更复杂也更好,即使某些process大小比内存还大,它还是能够运行。 实现的方法叫做Paging,它通过维护page table,用MMU(Memory Management Unit)将内存地址在virtual memory和physical memory之间转换。 virtual memory space的大小大于physical memory space,这就是大进程能在小内存运行的原因。
Paging
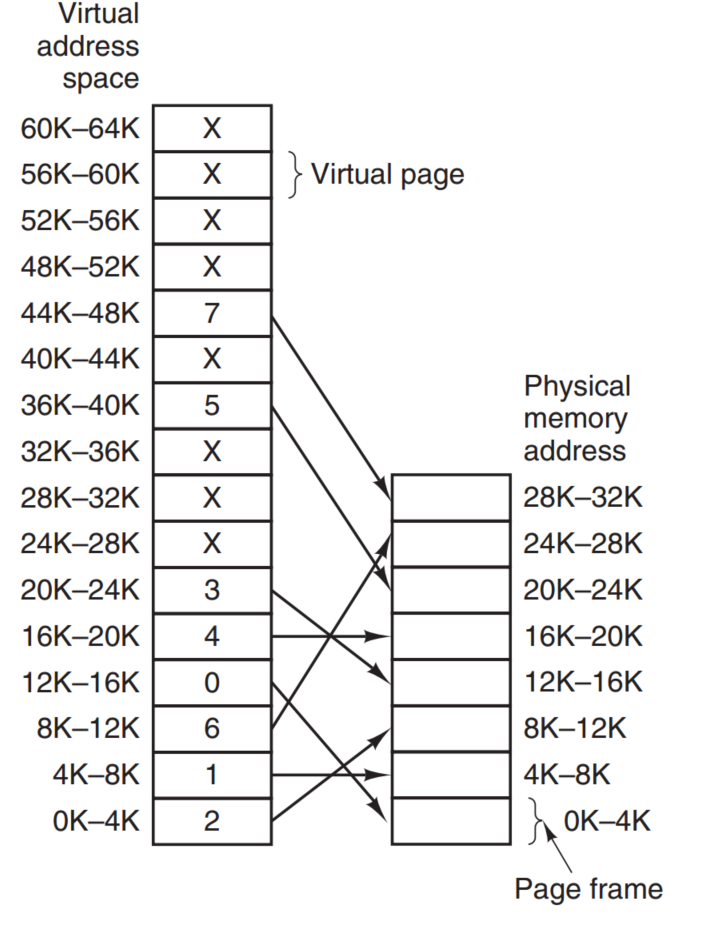
上图就是page table,左边是virtual memory的virtual pages,右边是physical memory的page frame。 除此之外,在实际的硬件中,还会保存*present/absent bit来追踪哪个page在memory中。
page fault:当virtual page不在physical memory中却要执行的时候,就发生了一次page fault,我们需要通过 Page replacement algorithms来把这个页面替换进去。
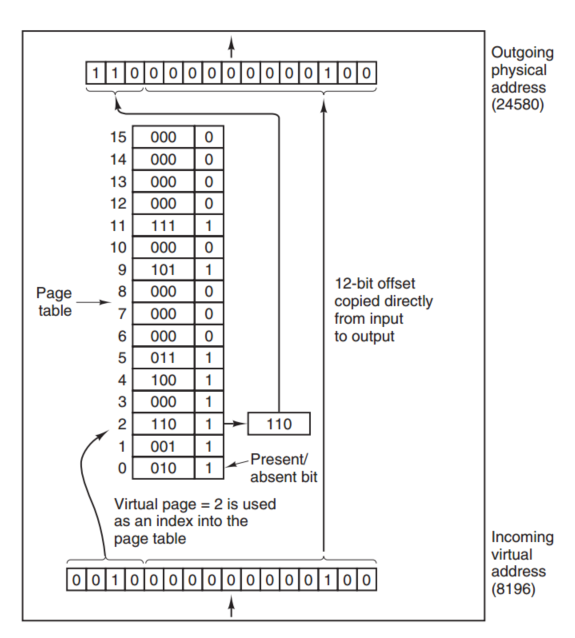
如上图所示,virtual address 8196转换为 physical address的过程是:
- 提取virtual address的前面四位:0010,在page table中找到相应的位置。
- 检查present bit,present bit为1,说明此page已经在physical memory中。
- virtual address 8196被转换为physical address 24580(加上offset)。 …
Structure of a Page Table Entry
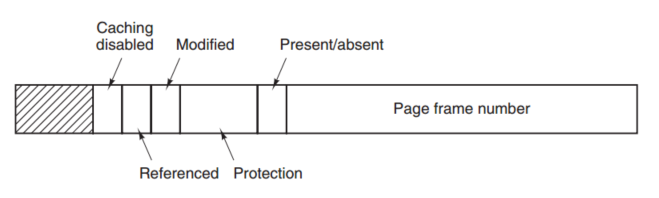
上图是一个典型的page table的entry。 最重要的当然是 page frame number,这是virtual address转换为physical address的关键信息。 Referenced bit: 这个Bit是给后面的page replacement algorithm使用的。 Modified bit: 如果此page的内容被write过,被置为1,也被称为dirty bit。
Speeding up Paging
此时来关于paging技术的一些细节,在任何的paging system中,要面对两个主要的问题:
- The mapping from virtual address to physical address must be fast.
- If the virtual address space is large, the page table will be large.
现在我们来谈谈如何加速paging: Translation Lookaside Buffers(TLB)。
通过维护一个TLB,每次需要转换的时候先访问TLB,如果TLB没有,再去访问page table。
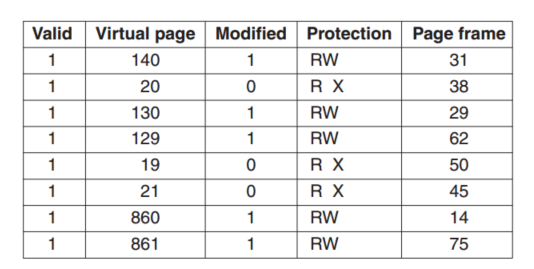
- If a virtual address is presented to MMU, the hardware checks TLB by comparing all entries simultaneously (in parallel).
- If match is valid, the page is taken from TLB without going through page table.
- If match is not valid
- MMU detects miss and does an ordinary page table lookup.
- It then evicts one page out of TLB and replaces it with the new entry, so that next time that page is found in TLB.
Page tables for large Memories
Multilevel Page Tables
使用多级page tables来解决page tables过大的问题。
多级page tables的实质是什么呢?
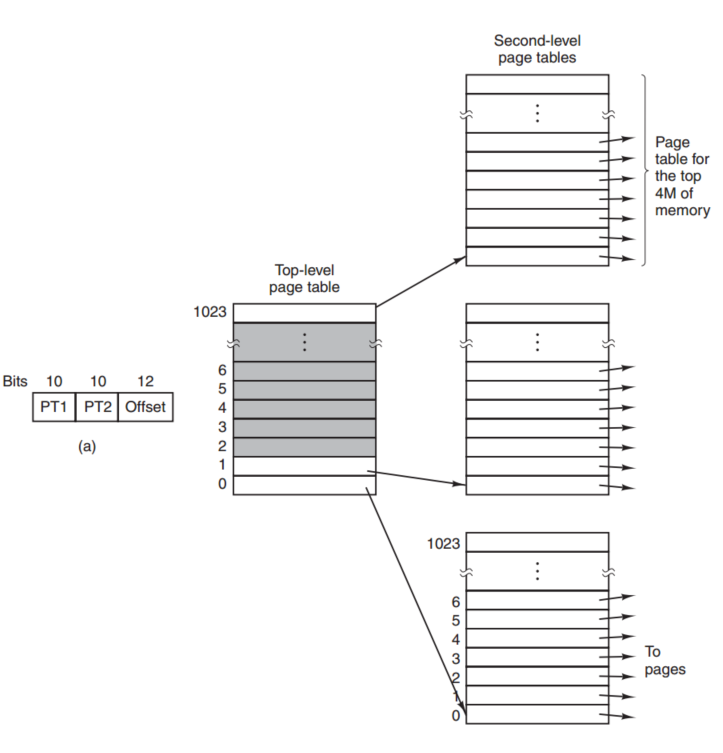
如上图所示,我们在转换的时候并不需要把整个page tables全部读进内存,找到第二级page tables,把相应的page tables读进内存就可以了。
Inverted Page Tables

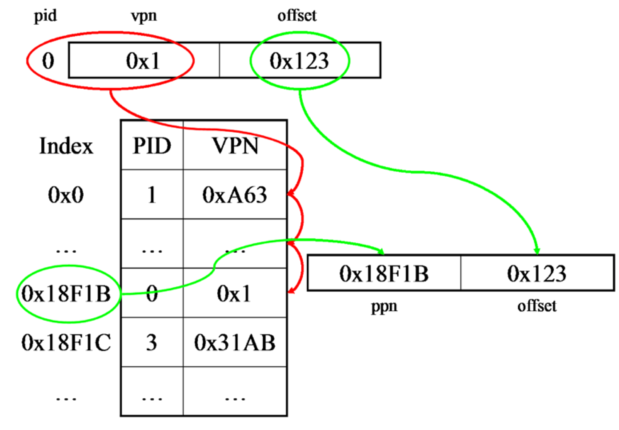
现在在介绍一下在inverted page table中physical address和virtual address之间的转换。
virtual address到physical address: 如上图所示,virtual address存在两个field:VPN & offset。而在page table中有两个field:PID和VPN,其实还暗藏着一项i,这个i就是某个entry在page table中的index, 比如上图 通过pid=0,VPN=0x1确定了某个entry,此entry的index= 0x18F1B,而index=ppn,physical address=ppn+offset,由此可确定physical address。
physical address到virtual address: 确定ppn=0x18F1B,然后在page table中找到entry的VPN=0x1,所以virtual address= 0x1 + offset。
Page Replacement Algorithms
The Optimal Algorithm
最优算法也就是每次选择替换的page距离下次被访问的时间都是最长的,但它是impractical的因为它需要预知未来。 但是能为其它算法提供参考。
First-in First-out
简称FIFO,通过维护一个queue,每次替换queue的head,如果hit了整个queue的序列不会发生变化。 FIFO的优点是:May be the page allocated very long ago isn’t being used anymore. 缺点:
- Doesn’t consider locality of reference。没有考虑局部引用性
- Suffers from Belady’s Anomaly,所谓的Belady’s Anomaly也就是说随着physical memory的增加,page faults的次数反而增加了!其中一点重要的原因是随着physical memory的增加,初始阶段肯定要 发生的page faults增加了。
The Second Chance Algorithm
利用page entry的reference bit,是FIFO的变形。 当此page hit的时候reference被设为1,而当MMU寻求page被替换时,也是从queue的head开始找,如果此page的reference是1,那么将reference bit置为0,然后把这个page放在queue的尾端。再找下一位。 所以,如果queue的page的reference bit 都为1,最终还是会回到原先的head,此时的reference bit=0,替换此页面即可。
The Clock Algorithm
The clock algorithm is a better implementation of second chance algorithm.
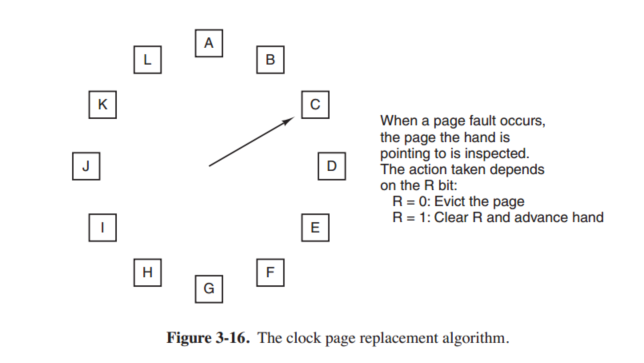
如图所示,如果page faults发生了,先检查当前指向的页面,如果reference bit=1,则清空再往下走,直到找到一个page的reference bit=0。
Not-Recently-Used
Enhanced second chance. Replace the page which is not used recently。同时考虑R和M位。 page被分成四个类。
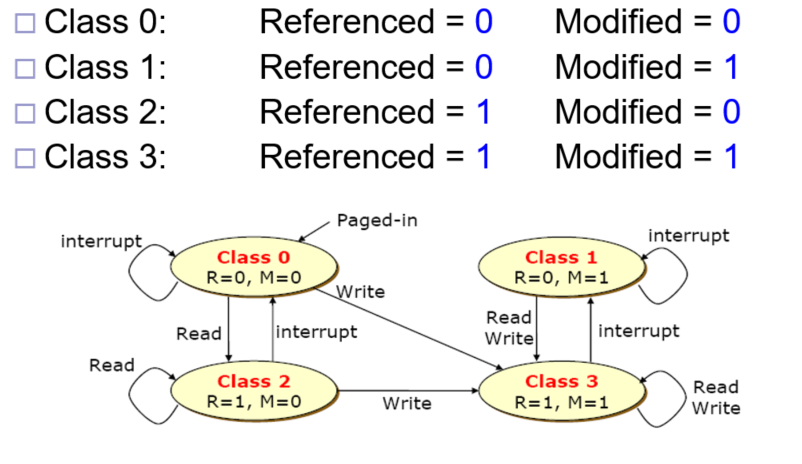
这是四个类之间的转换关系,如果要选择一个页面替换,先从类0里随机挑选一个,如果类0没有page,再从类1随机挑选一个…
Least-Recently-Used Algorithm
此算法在合适的条件下几乎是最优的算法,它基于”locality of reference”,获得了较好的性能。 存疑:这个算法看起来只是在FIFO的基础上加了一点改变,FIFO在hit的时候queue的顺序不变,而LRU则是将hit中的page放在queue的尾端。
优点:
- Quite efficient, good to apprpximate OPT.
- Does not suffer from Belady’s anomaly.
缺点:
- Its implementation is not very easy.
- Its implementation may require substantial hardware assistance. We have several ways to implement this algorithm, but very expensive.
Not-Frequently-Used
Simulated LRU. 设置一个clock interrupt,在每个clock interrupt里,OS查看每个page的reference bit,如果为1,加到它的counter上,如果为0,则不加。 每次替换counter最低的page。
缺点:
- Some page may be heavily used. 2 .有些page的counter可能过大,但是之后又不访问了,但是它还是会一直留在内存。
- This algorithm never forgets.
Aging Algorithm
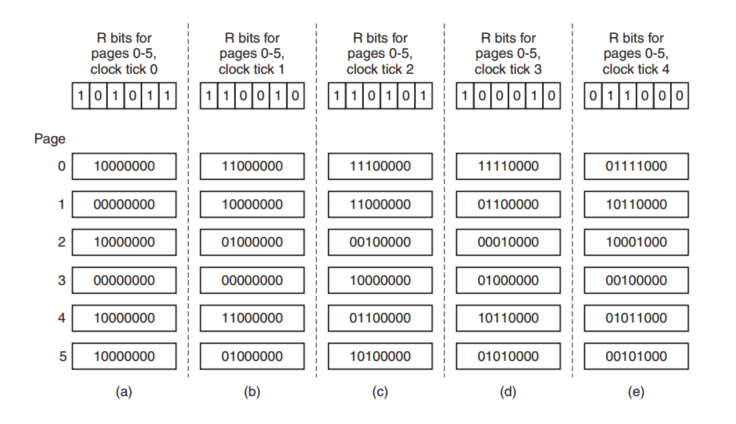
Modified NFU: NFU+forgetting
做法:每次clock interrupt时将counter右移一位(也就是除以2),然后在counter的最左端加上reference bit。
如下图所示:
Working Set Algorithm
先来介绍什么什么是working set工作集,也就是在在过去某段时间内访问过的page的集合。
Working Set算法: 如果reference bit=1,那么将此page的time设为当前时间,如果reference bit=0,那么看它是否在工作集中,如果不在,则替换。如果所有page都是referenced的,随机挑选一个。