本周星期三去参加了一场论文分享会,论文是遗传算法相关的,因为之前对这个领域只是一知半解,所以很多内容听的不是很懂,不如在每次分享会之前先把要研讨的论文看一遍,相信会受益更多。
下面是《Cooperative Co-Evolution With Differential Grouping for Large Scale Optimization》中第一和第二部分的读书笔记。
Part I
优化问题一直是算法领域的一个难题,原因在于它难以被直接解决,我们只能找到一个近似最优解(near-optimal),演化算法(Evolutionary Algorithm,EA)是一种解决此类问题的高效的算法。
EA
什么是EA呢?
In computer science, evolutionary computation is a family of algorithms for global optimization inspired by biological evolution, and the subfield of artificial intelligence and soft computing studying these algorithms.
——Wikipedia
也就是说演化算法其实就是对自然界进化过程进行模拟的一种算法,比如优胜劣汰等过程。
GA
遗传算法(Genetic Algorithm,GA)就是EA的一种。GA模仿了基因的选择过程,选择更好的基因遗传,通过基因的mutation、crossover等操作跳出局部最优解,尽可能找到全局最优解。
感觉这个算法和模拟退火算法有点像,或者说这类算法的内核其实都差不多?模拟退火算法其实就是对爬山过程的改进,如果一个问题有很多局部最优解,普通的爬山算法如果收敛到一个局部最优解就不会继续往下走了,你无法确定
这个局部最优解的质量,而模拟退火则是在爬山的过程中加入一定的概率跳向其它地方,模拟退火算法的结果优劣性就取决于你设置的这个概率参数,参数设置的好,你得出一个比普通爬山更好的结果,但是参数设置的差,你的结果
可能比普通爬山还要差,本质上像是一个大规模的随机搜索算法。为什么说内核差不多?其实就是在普通的爬山过程中加上一定的随机过程,GA是模拟基因的变异,而模拟退火是设置概率参数。
However, their performance deteriorates rapidly as the dimensionality of the problem increases。
也就是说,虽然EA对这类大规模优化问题很有效,但是一旦问题的维数(dimensionality)上升,它的有效性也要大打折扣,解决这个问题的方法就是Divide-and-Conquer,也就是将大问题分解(decompose)成小问题再各自求解。
Cooperative co-evolution (CC) has been proposed by Potter and De Jong as an explicit means of problem decomposition in evolutionary algorithms.
如此一来,Cooperative coevolution(CC)应运而生,所谓CC,也就是将问题分解成子问题再求解,根据分解的策略不同,CC的性能也各不相同。面对不同的问题,就有不同的分组策略,这篇论文用一种叫Differential Grouping的方法 实现了automatic decomposition。
Part II
Gene Interaction
这一部分是为了帮助读者理解Gene Interaction的概念,Gene Interaction和以下词在某种意义上等价:epistasis/linkage/nonseparability。
而关于separable的数学定义是这样的:
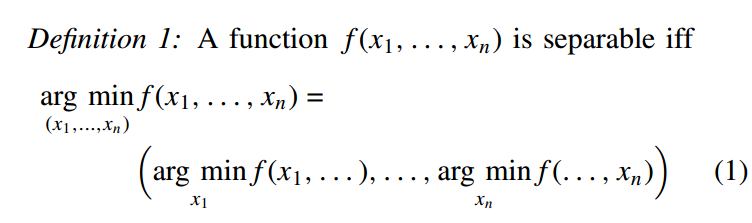
简单的来说,如果x1,x2…xn互不相关(即不存在x1*x2这样的项?),那么这个函数就是separable的。
Cooperative Co-Evolution
CC是解决大规模优化问题的有效方法,但是其对于分组策略非常敏感,然后作者开始介绍CC的发展过程。
- 在最初的CC,CCGA直接把n-dimensions问题分解成了n个1-dimension问题,但是这样的处理在Griewank function等nonseparable function上表现很差,原因就在于它根本没有区分这个函数是否是nonseparable,而是直接将其 分解成n个1-dimension子问题,又因为变量间的interdependence,所以在结果上表现的很差。
- 上面的例子最多只测试到了30-dimensions,更高的维数结果又会怎样呢?Liu et al首次将CC的框架用于解决1000-dimensions的benchmark problem,实验结果显示随着维数增加,CC表现的更好了,但是这个实验的function也是 nonseparable的。
- 将partical swarm optimization(PSO)用于CC框架(CPSO),CPSO将原本n-dimensions的问题分解成k个s-dimensions子问题,CPSP的缺点是没有在large-scale problems上测试过。(其实我不是很明白large-scale problem和high-dimensions problem的区别?)
- random grouping方式,将n-dimensions分解成k个s-dimensions,且是static grouping,这里我理解的static grouping是 在每次演化周期里随机分配,分组策略不随着周期的改变而变化就是所谓的static grouping, 但是在数学上表明,应用随机分组的方式,interacting variables之间在同一组的概率会更大(?why),所以说,这种方法对于interacting variables的个数极为敏感,CCPSO(CPSO的升级版本)已经能被用于解决1000甚至2000-dimensions的functions, 但是function的interacting variables的个数不能超过5个。
- 上面提及的分组方法都是先固定了k和s的值,所以当我们面对实际问题的时候,要根据情况选择不同的k和s,并且同一个问题不同的演化周期如果只有一个k和s的话算法性能会比较差(每一个周期的interacting variables的数量都
有可能不同),当interacting variables的数量多的时候,分组要少(s要大),反之亦然。MLCC应运而生,MLCC会先设置好一个包含有限个s的
s集合,面对不同的问题,选择能让算法性能更优的s,但是MLCC也是要事先确定好 这个s集合,所以我们现在需要一个automatic grouping的方法来帮助我们获得更好更智能的分组策略。
分组方法的总结
这一部分详细介绍了各种分组方法。
Random Methods
Pertubation
Interaction Adaptation
Model Building
Part III
开始进入正文,详细介绍此论文作者发明的能够实现auto grouping的方法,叫differential grouping。
Mathematical basis
Differential Grouping Algorithm
Time Complexity
Application With CC
Experimental settings
CEC’2010 benchmark functions
Parameter Settings
Analysis of Results
Conclusion
My Harvest
这大概是我第一次认认真真的将一篇论文从头读到尾,每个不清楚的概念都尽力去弄懂,各种查资料,查其它论文,很不容易,但是收获很大。
- 这篇论文的质量非常非常高,第一部分introduction和第二部分related works几乎可以看作近几年GA,EA的tutorial,介绍的非常详细而且易懂。
- 此论文的实验结果分析非常详实,对于每一个读者可能存在的心生疑惑的点,它几乎都有解释,很完美。
- 提出来的
differential grouping有数学上的理论基础,可供后来者在此模型上再做文章发枝散叶。 - 对于一篇论文各个部分应该讲些什么,一篇好的论文的结构该是怎样的,我有了更深的理解。