开始机器学习的学习啦!
让我们从经典的西瓜书开始。
1.1
人类通过“经验”来学习,是否可以设计一种算法让机器也来学习呢?机器学习便是一种这样的算法,说白了,机器学习就是一种learning algorithm,它教机器(computer)如何通过数据集(经验)来学习
得到模型。
1.2 terminology
了解一下机器学习里基本的术语。
data set
instance/sample
attribute/feature
training data\training set
hypothesis\ground-truth
label\example\lable space(label+sample=example)
- 预测离散值叫做classification。
-
预测连续值叫做regression。
- supervised learning:classification and regression。
- unsupervised learning:clustering
1.3 科学推理
induction是一个generalization的过程。
deduction是一个specialization的过程。
inductive bias
inductive bias即是所谓归纳偏好。机器训练出来的“模型”不止一个的时候,我们要如何选择?(比如根据一系列点我们可以画出非常多条符合这些点的曲线)。
Occam’s razor
Occam’s razor即是所谓奥卡姆剃刀原则。即“有多个假设与观察一致,则选择最简单的那个.”,可以说是很简单粗暴了。
NFL定理
什么是NFL定理?No Free Lunch Theorem。“没有免费的午餐定理”。假设我们有很多个学习算法,它们通过训练得到了不同的模型,也就是说,无论算法a多么的巧妙,算法b多么的简单,它们的期望性能是相同的。 它有一个重要的前提条件:所有问题同等重要。也就是说这么多模型里我们要选择当前问题最合适的。
2.1 empirical error and overfitting
error有两种,一种是training error,也叫empirical error,指的是与训练集的误差,另一种是generalization error,指的是与测试集的误差,后者可以用来评价模型泛化的能力。
所谓的error rate通常指代的是generalization error rate,error rate=1-accuracy。
那什么是overfitting和underfitting呢?西瓜书里的这张图非常形象。
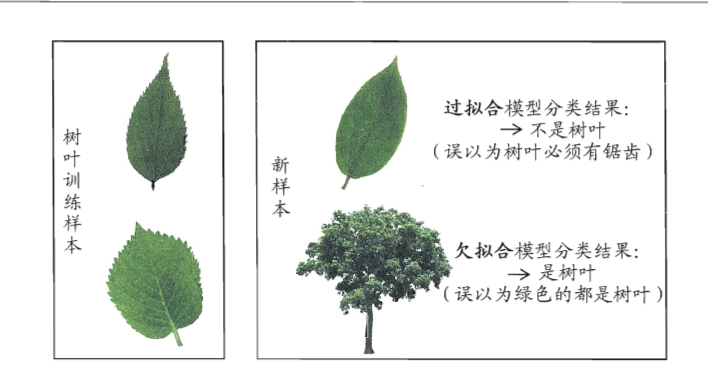
所谓overfitting过拟合就是指学习能力太强了,把属于这个训练集的不应该学到的特点也学进去了(如树叶的锯齿),而underfitting欠拟合则是指学习能力太弱。
2.2 评估方法
首先考虑一下测试集和训练集的关系,测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过,我们希望得到泛化能力强的模型,这里指的是对知识“举一反三”的能力,而不是只是在做“
做过的习题”时才会表现好。
对于一个包含m个样例的数据集D,通过对D进行适当的处理,从中产生出训练集S和测试集T。
hold-out
- hold-out留出法是指直接将数据集D划分为两个互斥的集合,即D=S∪T,S∩T=空集。
- 训练/测试集的划分要尽可能的保持数据分布的一致性。
- 单次使用hold-out得到的估计结果往往不够稳定可靠,一般采用若干次随机划分、重复进行试验评估后取平均值作为留出法的评估结果。
- S和T的比例关系会影响训练出来的模型,若S包含绝大多数样本,T比较小,那么评估结果可能不够稳定精确,如果T比较大S比较小,被评估的模型与D训练出来的模型可能有较大差别,从而降低了评估结果的保真性(fidelity)。
cross validation
cross validation也叫k-fold cross validation,而且通常会进行p次划分(原因和上面一样)。
cross validation把D分成k个子集,每次选择一个子集作为测试集,所以p次划分一共进行了p*k次训练/测试。
如果k=m,则是每次留一个样本作为训练集,这种特殊的cross validation叫leave-one-out,它的优点是评估结果往往被认为比较准确,缺点是当数据集比较大时,训练m个模型的计算开销可能难以忍受。
bootstrapping
bootstrapping自助法是指每次随机从D中挑选一个(放回)样本放入D’,执行m次后得到一个包含m个样本的数据集D’,做一个简单的估计,样本在m次采样中始终不被采样到的概率是1/e=0.368。也就是说,我们可以将D’作为训练集 ,D\D’作为测试集。bootstrapping在数据集较小、难以有效划分训练/测试集时很有用,但是它可能会改变原有初始数据集的分布,引入估计偏差。
2.3 performance measure
对学习器的泛化性能进行评估,不仅需要切实可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是performance measure性能度量。
- error rate & accuracy.
- 查准率:预测为正例中实际为正例的比例。查全率:实际为正例中被预测为正例的比例。
- P-R图:按照可能性的大小降序排列,按此顺序逐个将样本作为正例进行预测得到的查准率-查全率曲线。
- BEP(Break-Event Point),查全率=查准率时的取值。
- F1/Fβ,当β=1时为标准的F1度量,β>1时查全率有更大影响,当β<1时查准率有更大影响。
- ROC体现了排序本身的质量好坏。FPR。
- 代价敏感曲线和代价曲线。