Three Steps for Deep Learning
如果你学过机器学习,知道什么是 model 和goodness,那么其实你也懂深度学习。
回顾机器学习,我们接触到的第一个模型大概会是 linear model,确定模型之后,再决定损失函数长什么样,确定data set,用梯度下降等方法去优化此损失函数,令lost最小,最后得到一个参数确定的函数,这个函数就是训练的成果。
我们所做的努力,其实就是为了训练出一个函数让其逼近某个目标函数。
所以我们可以将机器学习分为三部曲:
- model
- goodness of function
- pick the best function (optimization)
在深度学习中,其实就只是改变了第一步的model而已,机器学习的model是 linear model, logistic regression, svm
等,深度学习的model是各种neural network,model更复杂了,仅此而已。
What is Neural Network?
要学习神经网络,不如先来看看 fully connect feedforward network 长什么样。
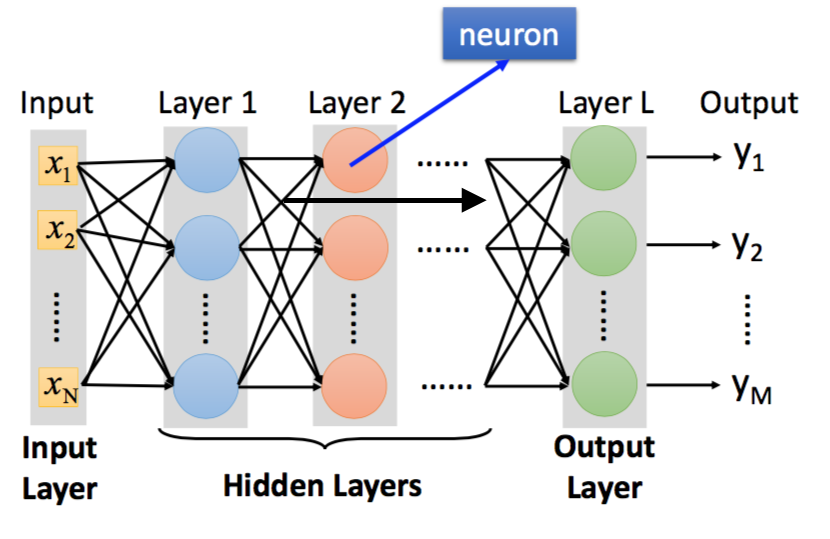
整个fully connect feedforward network可以分成四个部分:input layer、hidden layers、output layer 和 output。
hidden layers可以有很多层,每一个layer可以有很多neurons,具体的层数和神经元数可以自己去设计,当你确定好这个network的结构时,model就已经确定好了,这里的model也可以表示李老师所说的”function set”。之所以叫fully connect feedforward network,是因为在这个network中,前一层和后一层是全连接的,即前一层的全部神经元与后一层的每个神经元都进行了连接,并且此network是一层一层向前推进的,所以是feedforward(?关于feedforward的解释是笔者猜想)。
Why Deep?
李老师在ppt里给了一个很有趣的定理: Univerality Theorem。
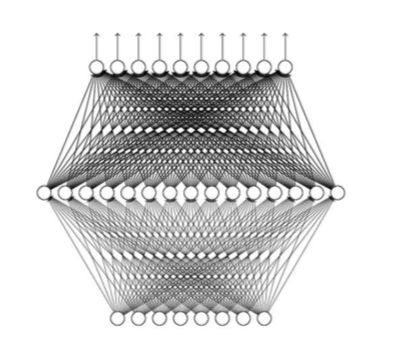
关于此定理,可以做以下阐述:只要神经元的数量足够多,那么只用一层hidden layer就能实现任何的网络结构。即此网络能够模拟任何的函数。
这是一个非常深刻的结论,深刻到我们可以提出这样一个问题:既然一层hidden layer就足够了,那么deep learning的deep还有意义吗?
李宏毅老师告诉我们,将网络的结构分成很多层,可以更好的体现modularization。就算一层hidden layer的network能够表示所有的network,但是这样的network效率很差,很有可能因为开销过大,这个network根本训练不出来。而modularization能够帮助我们更好的设计网络结构,将一个hidden layer分成几个hidden layers,不仅能帮我们更好的理解网络结构每一层的意义,而且效率更好,效果可能也会更好。
之前有听说过一个将”机器学习“比喻成”炼金术”的观点,研究人员并不知道为什么有些算法会起作用而另一些则不会,他们只是简单的将训练集和模型丢进电脑,效果不好则加更多的参数,这背后没有一个”理论”能够解释模型为什么work。在我看来,为了去解释模型为什么work,上述所说的modularization是很有必要的,如果我们就只是用一个超级计算机去训练出一个看似效果很好的模型,而不做更加深入的思考,是很可怕的一件事,我们做出来的”不能理解”的系统会不会在哪天突然崩塌呢?
Modularization
李宏毅老师的ppt里有一个很生动也很神奇的例子,可以解释”modularization”如何帮助我们理解网络结构。

上图是语音识别(speech recognition )一个技术流程,里面的每一步都是由语音专家们经过长时间摸索得来的,很有趣的是,如果我们用深度学习去做语言识别会发生什么呢?

我们将深度学习神经网络的hidden layers分成五层,训练出来的每个layer是不是对应上面语音专家们总结出来的步骤呢?这样的话,对于此神经网络的每一层,是不是都能找到其意义所在呢?这样的深度学习,是不是就不再是空中楼阁了呢?