卷积神经网络(Convolutional Neural Network, CNN)通常被用于图像领域,但普通的神经网络(比如Fully connect feedforward network)也能处理图像,为什么还需要CNN呢?
CNN的出现是因为研究者观察到图像由一些特别的性质,如果把这些特性利用起来,可以简化原来的神经网络,所以,CNN其实比普通的神经网络更简单。
Three property of CNN
- Some patterns are much smaller than the whole image
- The same patterns appear in different regions
- Subsampling the pixels will not change the object
Propert One
第一个性质告诉我们,一个pattern可能只是一张图片的某一小部分,所以如果我们要去识别这个pattern,我们不必去看整张图片。

比如我们要识别上图的鸟喙,其实不必去看整张图片,因为鸟喙只是整张图片的一部分。
这个性质反映在网络结构上则是:前一层与后一层做的并不是全连接,而是部分连接。
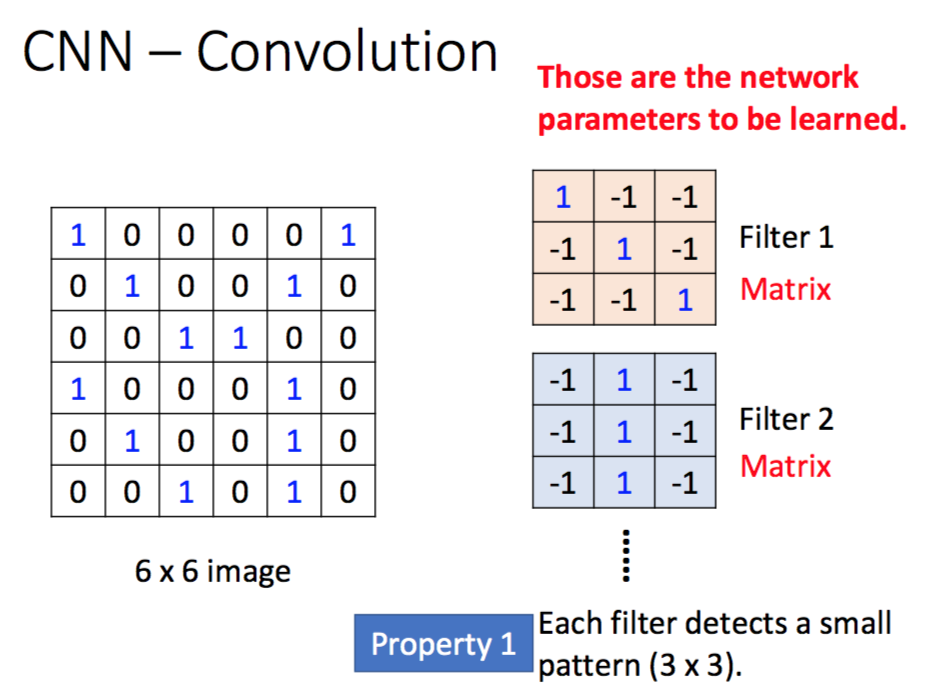
这个性质反映在具体的CNN模型中,则是某个Filter与图片的某个部分做卷积,如上图所示。
Property Two
第二个性质是在说,同一个pattern可能会出现在图片的不同位置。

如上图所示,同样是鸟喙,出现在了图片的不同位置,为此,我们需要去将Filter与图片的不同部分做卷积。

如上图所示,3x3 的Filter 1与 6x6的image做了 4x4次矩阵卷积。
这个过程有点像是我们拿一个鸟喙的模型,一部分一部分的去对比图片,找出图片的鸟喙,可以看到,当鸟喙出现时,这个部分所对应的卷积值比较大。
Property Three
这个性质告诉我们,一张图片经过部分取样之后,不会发生太大的变化。

所以,在CNN的Max Pooling中,就可以取4个值中最大的一个来”部分取样”。

The whole Process of CNN
CNN的整个流程如下:

What does CNN Learn?
CNN与普通的DNN有什么本质不同呢?CNN究竟学了些什么?

CNN其实与DNN并没有本质上的不同(笑)。